现代AI爬虫的进化之路:从OCR到Markdown的完美转身 🚀
By LayFz on Jul 4, 2025
前言 💭
最近在搞爬虫项目的时候,发现了一个很有意思的现象:现代爬虫必须要有AI加持才能玩得转!🤖 传统的正则表达式抓取方式已经被AI狠狠地”降维打击”了,效率提升不是一点半点。
但是,理想很丰满,现实很骨感… 😅
现有方案的痛点 😵💫
📝 纯文本类型
- 案例:新闻文章、博客内容
- 处理难点:相对简单
- 现有方案问题:基本能处理
🖼️ 图片+文字类型
- 案例:产品介绍页面、技术文档
- 处理难点:OCR识别准确率、中文字符识别
- 现有方案问题:百度OCR经常识别错误,需要人工校验

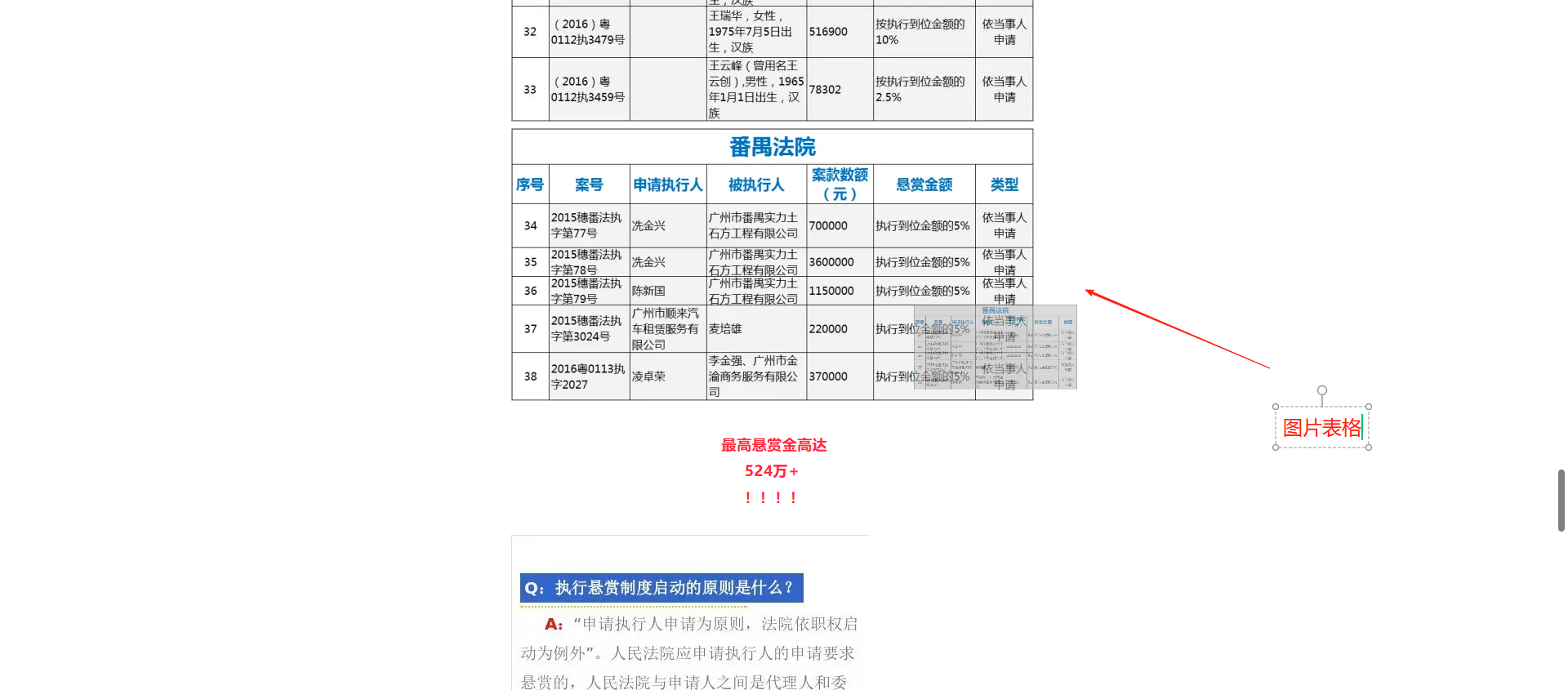
📊 图片+表格类型
- 案例:财务报表、数据统计页面
- 处理难点:表格格式丢失、行列关系混乱
- 现有方案问题:OCR无法保留表格结构,AI理解困难
多模态大模型的”美丽陷阱”
说到AI爬虫,大家第一反应可能是:“用多模态大模型啊!ChatGPT不香吗?” 🤔
emmm… 香是香,但是有几个问题:
-
中文理解能力有限 🈹
- 毕竟是国外的大模型,中文训练还是有些欠缺
- OCR识别中文的准确率让人捉急
- 我们项目不允许有错误数据,所以直接pass
-
API支持不够完善 📡
- 大部分支持API的多模态模型还没完全开放
- 即使有,成本也不低
所以我们选择了国产大模型DeepSeek,至少中文理解能力杠杠的!🎯
数据结构的”混乱现状”
我们项目遇到的数据结构简直是”百花齐放”:
- 📝 纯文本:这个还好处理
- 🖼️ 图片+文字:需要OCR配合
- 📊 图片+文字+表格:这就头大了…
更要命的是,图片里经常混杂着我们需要的信息,但也有很多无用图片,程序很难自动筛选。
当前方案的”冗余困境”
我们现在的流程是这样的:
获取文本和图片 → 图片丢给百度OCR → 拼接完整文章 → 投给DeepSeek提取数据问题来了:
- ❌ 流程冗余:步骤太多,效率低
- ❌ 通用性差:每个网站都要调整
- ❌ 表格处理弱:OCR无法保留表格格式
- ❌ 噪音太多:无用图片干扰数据提取
灵感闪现:Markdown才是王道!💡
突然想到一个问题:为什么不直接用Markdown呢?
想想看,Markdown的优势:
✅ 纯文本格式 - 轻量级,易处理
✅ 格式友好 - 保留基本样式和结构
✅ AI友好 - 大部分模型输出都是Markdown
✅ 通用性强 - 一套流程走天下
解决方案:PDF转Markdown的完美方案 🎯
经过一番调研,发现了一个神器:MinerU!
核心思路
网页 → PDF/图片 → Markdown → AI提取数据为什么选择MinerU?
🔍 项目地址:https://github.com/opendatalab/MinerU/tree/master
优势清单:
- 🇨🇳 中文友好:识别中文准确率极高
- 📐 排版自然:保留原有格式和结构
- 📊 表格支持:完美处理表格数据
- 🎯 精准识别:汉字识别准确度很高
- 🔄 数据完整:不丢失关键信息
实际效果
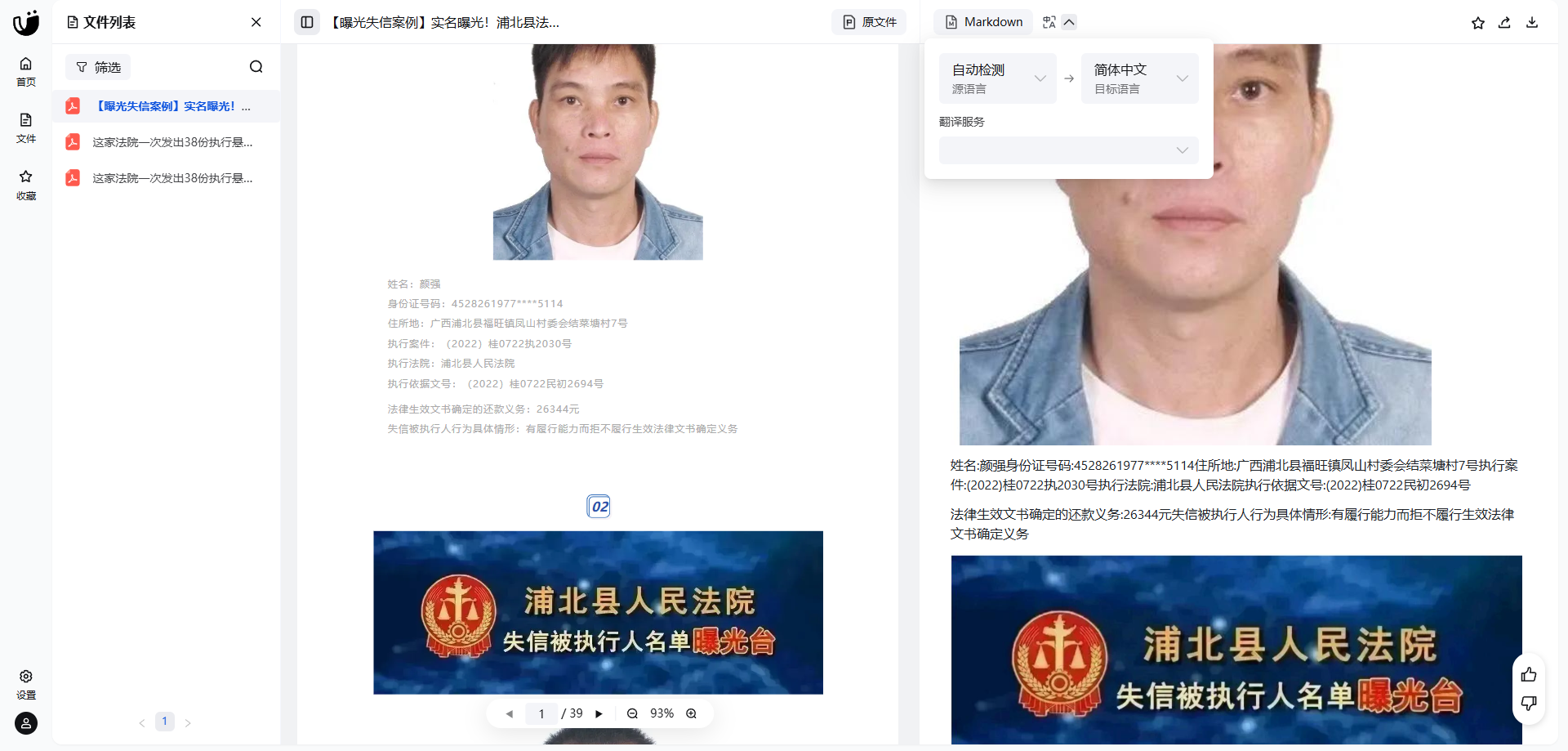
使用MinerU转换后的Markdown数据投给AI:
- ✅ 数据完整性 - 不丢失任何关键信息
- ✅ 格式保持 - 表格、列表等结构完整
- ✅ 噪音减少 - 无用图片被过滤
- ✅ 处理效率 - 一步到位,省心省力
总结 🎊
从传统的正则表达式,到OCR+AI的组合拳,再到现在的PDF转Markdown方案,AI爬虫的进化之路充满了惊喜!
核心观点:
- 🤖 AI加持是必然趋势 - 告别正则表达式时代
- 🎯 选择合适的模型 - 根据业务需求选择中文友好的模型
- 📄 Markdown是最佳载体 - AI友好且保留格式
- 🔧 工具选择很重要 - MinerU这样的工具能事半功倍
现在的方案不仅解决了数据混乱的问题,还大大提升了提取精度和效率。如果你也在做类似的项目,强烈推荐试试这个方案!🚀
怎么样,这波操作是不是很6? 😎